IT之家 5 月 29 日消息,Anthropic 今天(5 月 29 日)宣布推出旗舰新模型 Claude Opus 4.8,主打更强的智能体编程、多领域推理和知识工作能力。
官方表示,相比较 Opus 4.7 模型,本次 Opus 4.8 更新幅度较小,在保持价格不变的情况下,主要提升编程、智能体、推理和知识工作等用户能感知的方面。

能力层面,官方援引多家早期测试方反馈称,表示 Opus 4.8 “更可靠,判断也更敏锐”,在复杂多步骤任务中判断更稳,能主动提问、识别自身错误,并在计划不合理时提出异议。
官方评估显示,和前代相比,Opus 4.8 放任自己所写代码缺陷、却不加说明的概率低了约 4 倍,更愿意主动标出不确定性,减少缺乏依据的结论。
对齐表现方面,Opus 4.8 在支持用户自主性、按用户最佳利益行动等亲社会指标上创下新高。与此同时,欺骗等失配行为的出现率低于 Opus 4.7,并与 Claude Mythos Preview 接近。IT之家附上相关截图如下:

配套功能方面,claude.ai 新增 effort 程度控制,用户可平衡更高质量与更快响应。默认是 high 档,在编码任务中,token 消耗与 Opus 4.7 默认档接近,但效果更好;若选择 extra(在 Claude Code 中为 xhigh)或者 max 更高档位,模型会消耗更多 tokens 以换取更优结果。
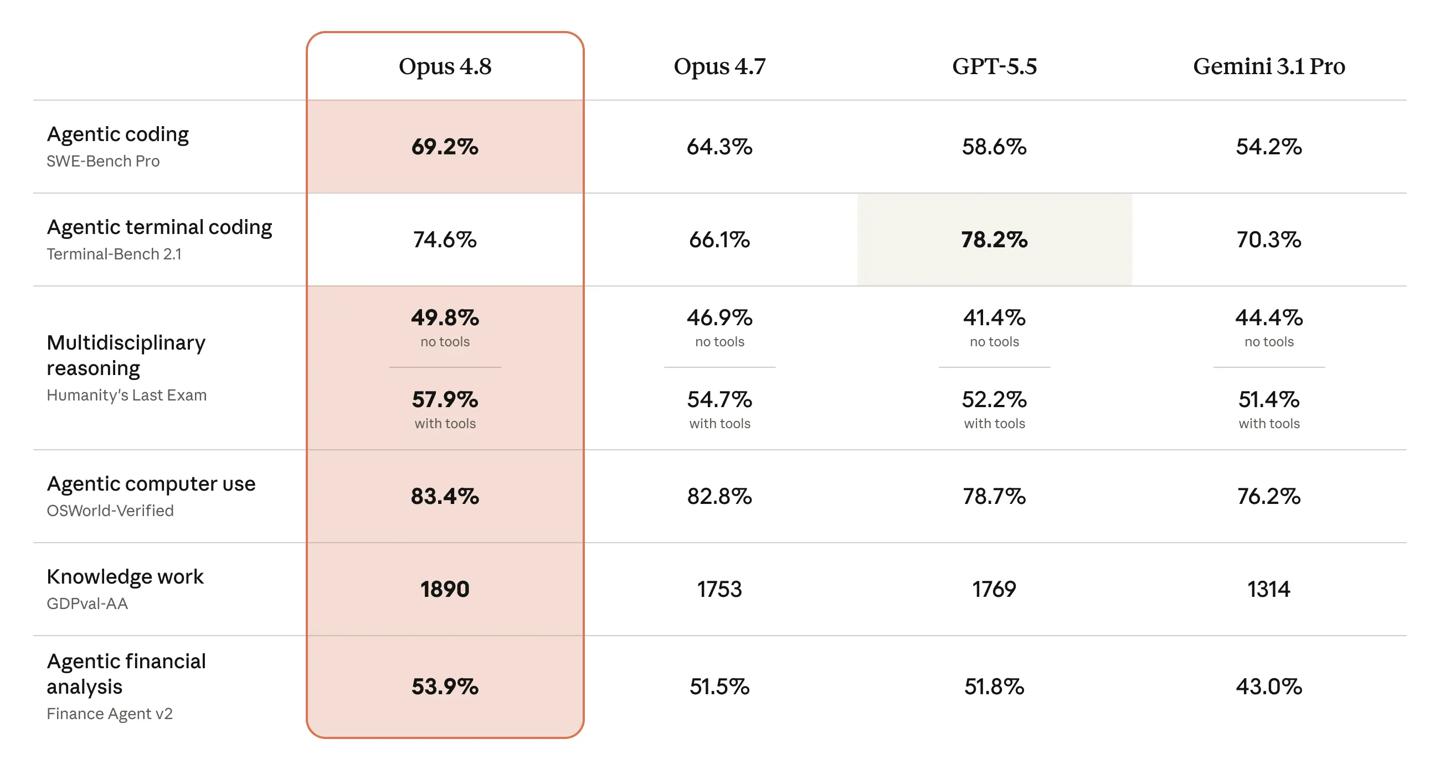
基准测试方面,Anthropic 称 Opus 4.8 在 SWE-Bench Pro 上得到 69.2%,并在该测试和其他多项基准中超过 GPT–5.5 与 Gemini 3.1 Pro。但在终端编程基准上,GPT–5.5 仍然领先。
这次更新还带来性能和价格调整。Anthropic 表示,Opus 4.8 的快速模式运行速度提升到 2.5 倍,模型成本则降到此前模型的 1/3。
定价方面,常规模式维持每 100 万输入令牌 5 美元、每 100 万输出令牌 25 美元;快速模式为每 100 万输入令牌 10 美元、每 100 万输出令牌 50 美元。